6.S081
添加用户函数
在 Makefile 的 UPROGS 处添加
添加系统调用
系统调用的用户空间代码在user/user.h和user/usys.pl中。
内核空间代码是kernel/syscall.h、kernel/syscall.c。
在 Makefile 的 UPROGS 处添加
系统调用的用户空间代码在user/user.h和user/usys.pl中。
内核空间代码是kernel/syscall.h、kernel/syscall.c。
RT,如果要公网访问服务器的 Redis,要将 redis-cluster 部署在公网上(似乎是废话,但是如果 Redis 服务发现端口是本地的话,就没法公网访问)。
config 中有几个很重要的参数:
# redis-cluster.conf
cluster-announce-ip 116.205.130.21 # 公网ip
cluster-announce-port 8003 # redis service 暴露给外部的端口
cluster-announce-bus-port 18003 # redis 集群总线端口
其他就不说了,主要是总线端口,它是 cluster 服务发现的端口,如果填的是局域网 ip(192.168.xxx.xxx)那么就无法被外部访问,因为在 Redis 对 key 进行 hash 的时候,如果处理 key 分片不是本 Redis 服务器的话,会提示Redirected to slot [5798] located at 192.168.xxx.xxx:$xxx(重定向到其他 Redis 服务器),无法被公网访问。
所以要将 cluster 服务发现的 ip 设为公网 ip,还要记得在服务器上暴露服务 ip 和服务发现 ip 以及关闭对应的防火墙。
完成 Multi-Raft
lab4A:完成 Multi-Raft 控制中心(和 lab3 内容差不多,一句话来说就是 shardctrler 是一个将 Config 作为日志进行维护的单 Raft 集群,并且不需要实现快照和持久化) 需要注意的地方是执行节点的 Join 和 Leave 操作时 shards 应该怎么平均且有序地分配给 gids(注意在 Leave 操作中,Group 里面可能有多余的 gid,此时需要注意将其算在 gids 里面),主要逻辑和 lab3 差不多,比较简单。
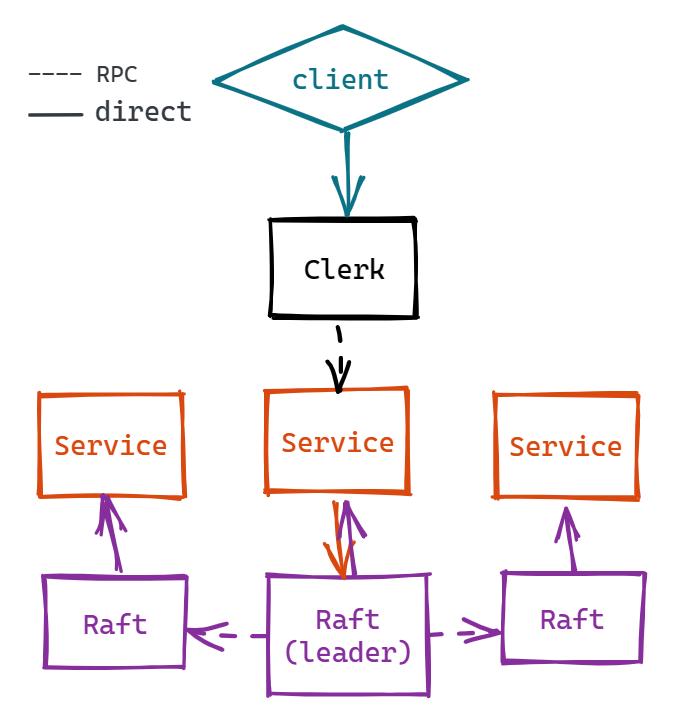
在 raft 框架的基础上建立一个容错的 KV 数据库。重点在于理解 Service 层和 Raft 层的交互,代码方面较为简单,故不进行赘述。
值得一提的是在写完 lab3 的大概框架后,TestSpeed3A 一直不通过,因为要求是平均 33ms 一个 commit,但正常来说 commit 时间应该和 heartbeat timeout 差不多,遂修改 Start() 函数,在 command 被 Service 送来的时候发起一次心跳,进行日志同步。
完成 Raft 的快照功能(涉及到较多的与 Service 层的交互。
|
|
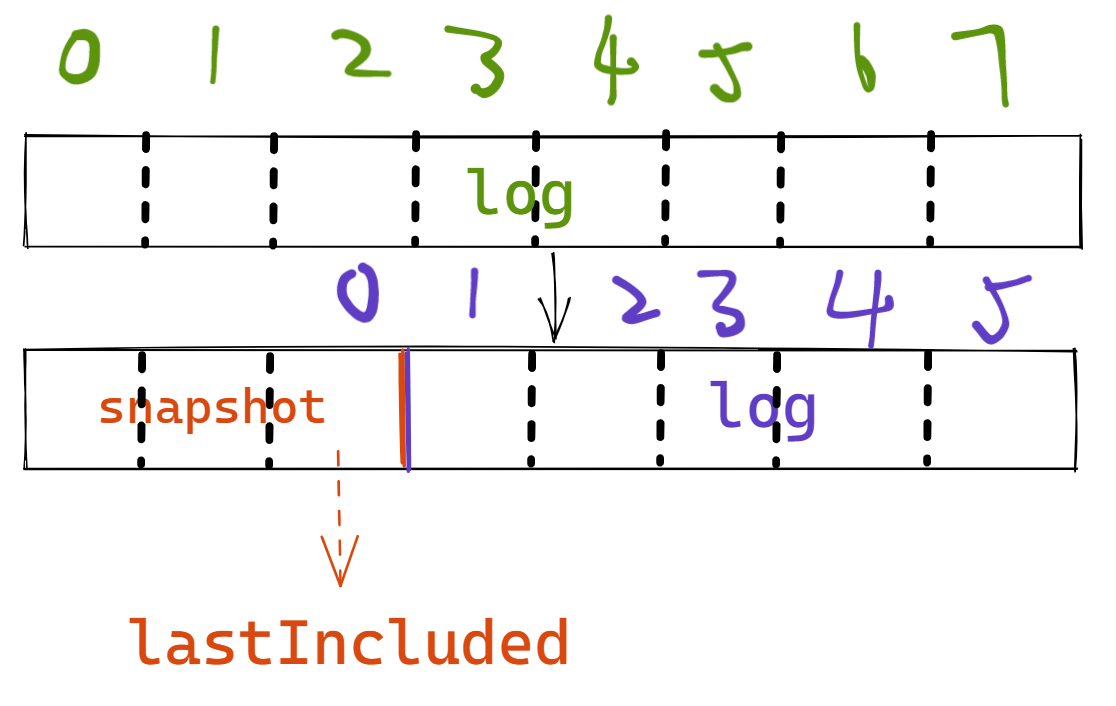 2. InstallSnapshot:
2. InstallSnapshot:
完成 Raft 的持久化。
如果前面做得好,只需要完成持久化。
|
|
|
|
|
|
|
|
If election timeout elapses without receiving AppendEntries RPC from current Leader or granting vote to Candidate: convert to Candidate.
处理日志,具体来说是接收 Service 层发来的日志,日志复制,应用日志。
涉及到一点 Raft 层与 Service 层的交互,比如 Leader 接受 command 并保存为日志;Apply 日志到 Service 层。
|
|
|
|
|
|
|
|
|
|
|
|
If you follow the rule from Figure 2, the servers with the more up-to-date logs won’t be interrupted by outdated servers’ elections, and so are more likely to complete the election and become the Leader.
完成各种情况的领导人选举。
我们首先需要熟悉一下 Raft 的工作原理,建议先过一遍 前置芝士。
rf.ticker() 对超时进行检测。那么是用time.Sleep还是time.Timer实现呢?官方的建议是用 sleep,但我用的是 timer,也能够正常实现,并且我还实现了 sleep 的版本,感觉速度上相差无几。
|
|
|
|
|
|
Candidate 选举前要先自增 currentTerm。