Raft
Raft 是一个实现分布式共识的协议,主要解决的是分布式一致性的问题。
Overview
假设现在有一个 Raft 架构的服务。我们将这个服务分为三层,Client,Service,Raft。Client 层首先发送请求给 Service 层,然后 Service 层解析请求为command,将command发送给 Raft 层的 Leader。Leader 在一定时间内通知 Service 层 “apply” 包含这个command的日志,Service 层才可以将这条日志保存到状态机,进而返回对应的结果给 Client 层。并且因为 Raft 层不应该存储过多的 log,所以 Service 层还会将 applied 的 log 压缩成快照,以便快速应用。
我们的任务就是用 go 实现基础的 Raft 层架构。
- 领导人选举
- 最初,所有 Raft 节点都是 Follower,如果在
election timeout内未收到当前term的heartbeat,就会转为 Candidate。election timeout: 选举超时时间。大概是heartbeat timeout的 3 倍。term:任期。每个用于实现一致性共识。heartbeat:心跳。Raft 节点有三种状态:Follower,Candidate,Leader。Leader 为了维持自己的领导,需要每隔一段时间发送一次心跳。
- 转为 Candidate 之后,
term++,给自己投票,并发送请求投票的 RPC 给 peer 节点。 - 收到请求 RPC 的 peer 满足以下两个条件才可以投票:
- peer 任期小于 Candidate 的任期或者 peer 任期等于 Candidate 并且当前任期没投过。
- peer 的 log 没有 Candidate 新。
- Candidate 得到的票数超过半数的 peer 就可以成为 Leader,因为上述限制,一个集群同一个
term只会选出一个 Leader。 - Leader 每隔一次
heartbeat timeout就发送一次包含 snapshot 或 log 的 heartbeat,发送快照还是日志根据 peer 的nextIndex而定。nextIndex是 Leader 对 peer 日志长度的乐观推测,成为 Leader 后会对所有 peer 的nextIndex赋值为自己的lastLogIndex+1,而后会根据 heartbeat 结果更改nextIndex。lastIncludeIndex每个节点都有,表示 snapshot 包含的最后一个日志的下标,初始为 0。- 如果 $nextIndex \leq lastIncludedIndex$ ,发送 InstallSnapshot RPC,否则发送 AppendEntries RPC。
- Follower 需要对 Leader 发送的心跳进行处理。
- 日志复制
-
Service 层会通过 Start(cmd) 发送 command 给 Leader。
-
Leader 需要保存 command 至 log,并在心跳的时候向 Follower 发送他没有的 log。
-
Leader 等待一半以上的 Follower 写入自己的日志,再进行 commit。
- 判断 Follower 写入日志的标准是
matchIndex,上面有提到nextIndex是 Leader 对 peer 日志长度的乐观推测,matchIndex则是相对悲观的推测,只有在 AppendEntries RPC 返回成功后 Leader 才会更新相应 Follower 的matchIndex。 - 并且考虑 RPC 调用的非线性返回,需要在修改
matchIndex的时候判断需要修改的值是否真的大于当前的matchIndex的值。
- 判断 Follower 写入日志的标准是
-
Leader commit 后修改
commitIndex的值,并另开一个 go routine 将从lastApplied+1到commitIndex的值推到applyCh,再修改lastApplied = commitIndex。 -
Follower 在 Leader commit 后也会以 Leader 的 commitIndex 作为限制 commit 自己的 log,并和 Leader 一样,将日志交给 service apply。
- 日志压缩
- Service 层在若干 commit 后,会压缩已提交的日志,并通过 Snapshot(index,snapshot) 提醒 raft 层。
- raft 层则需要进行一些处理,比如删掉被压缩的日志,改变日志的索引方式,持久化 snapshot 的信息(但不需要保存 snapshot,snapshot 仅存在 Service 层)。
- 对于 Leader,在 heartbeat 时,若满足 $nextIndex \leq lastIncludedIndex$ ,则通过
persister.ReadSnapshot()读取 snapshot 给 Follower。 - 如果 Follower term <= Leader term,只能接受 snapshot,并删掉被压缩的日志,改变日志的索引方式,持久化 snapshot 的信息。
Tips
-
注意 data race,对大部分 rf 结构的修改和读取都要上锁。
-
所有 RPC 都要检测任期,并对过期状态进行处理。
-
在 lab2D 中,需要改变下标的索引方式。
Each log entry also has an integer index iden-tifying its position in the log.
但这个其实很容易改,所以推荐在 2D 之前不要去管下标的问题,直接用 log 数组自己的下标就可以了。
struct
|
|
res
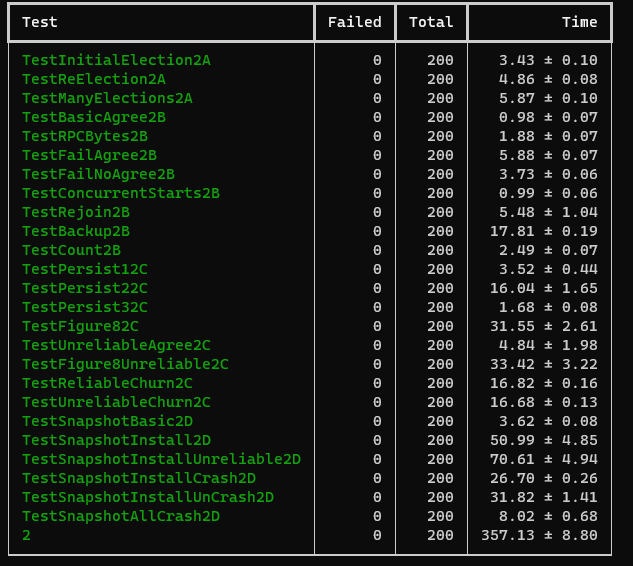
reference
https://thesquareplanet.com/blog/students-guide-to-raft/
https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf
https://pdos.csail.mit.edu/6.824/notes/raft_diagram.pdf
http://thesecretlivesofdata.com/raft/
https://pdos.csail.mit.edu/6.824/labs/raft-structure.txt
https://pdos.csail.mit.edu/6.824/labs/raft-locking.txt
https://blog.josejg.com/debugging-pretty/
https://flaneur2020.github.io/2020/11/07/mit6-824-raft/
https://github.com/OneSizeFitsQuorum/MIT6.824-2021/blob/master/docs/lab2.md