本文将会介绍 IPFS 以及 IPFS Cluster 的原理,并且简述 https://github.com/loomts/ipfs-clsuter 的纠删码优化以及测试的细节。
IPFS
IPFS 是一个分布式文件系统,其最大的特点是内容寻址,能够将文件的 CID 作为索引,在世界各地获取文件的内容。
具体来说,IPFS 在存储文件的时候,会将文件分成默认 256KB 的数据块,同时也会生成一些元数据块,用于存储其他块的 CID,最终会组成一个 Merkle DAG(与 git 的数据结构类似)。
如果文件有部分内容被修改,IPFS 只会将被修改的部分切割成小块,并构成一颗新的 Merkle DAG。因为 IPFS 的底层存储可以随意更换,可以用 linux 默认的文件系统,也可以用其他 KV storage,IPFS 默认使用的是 pebble。
IPFS Cluster
IPFS 虽然能通过 BitSwap 等机制从对等点获取数据块,但是无法保证对等点存在自己需要的数据,即无法进行方便的容错。
IPFS Cluster 作为 IPFS 的集群管理工具,提供了多副本容错机制,能够让集群通过 CRDT 或 Raft 共识算法将元数据和存储的数据保持一致,并且能够管理集群成员的状态。
IPFS Cluster With EC
EC 即 Erasure Coding,使用的是 Reed-Solomon 码,能够通过等长的数据分片生成若干校验分片,并且使用部分分片进行数据恢复。
在 IPFS Cluster 里面实现 EC 首先需要获取文件块,将文件块组装成等长的文件分片,进而再进行 RS 编码和额外的校验分片存储。
分片的分配方式是通过将 hash(filename+peerID)作为键值进行排序,排序得到的 peerIDs 将会被分为存储数据分片和校验分片的两类节点。对于这个文件,每类节点分别存储对应类型的分片。
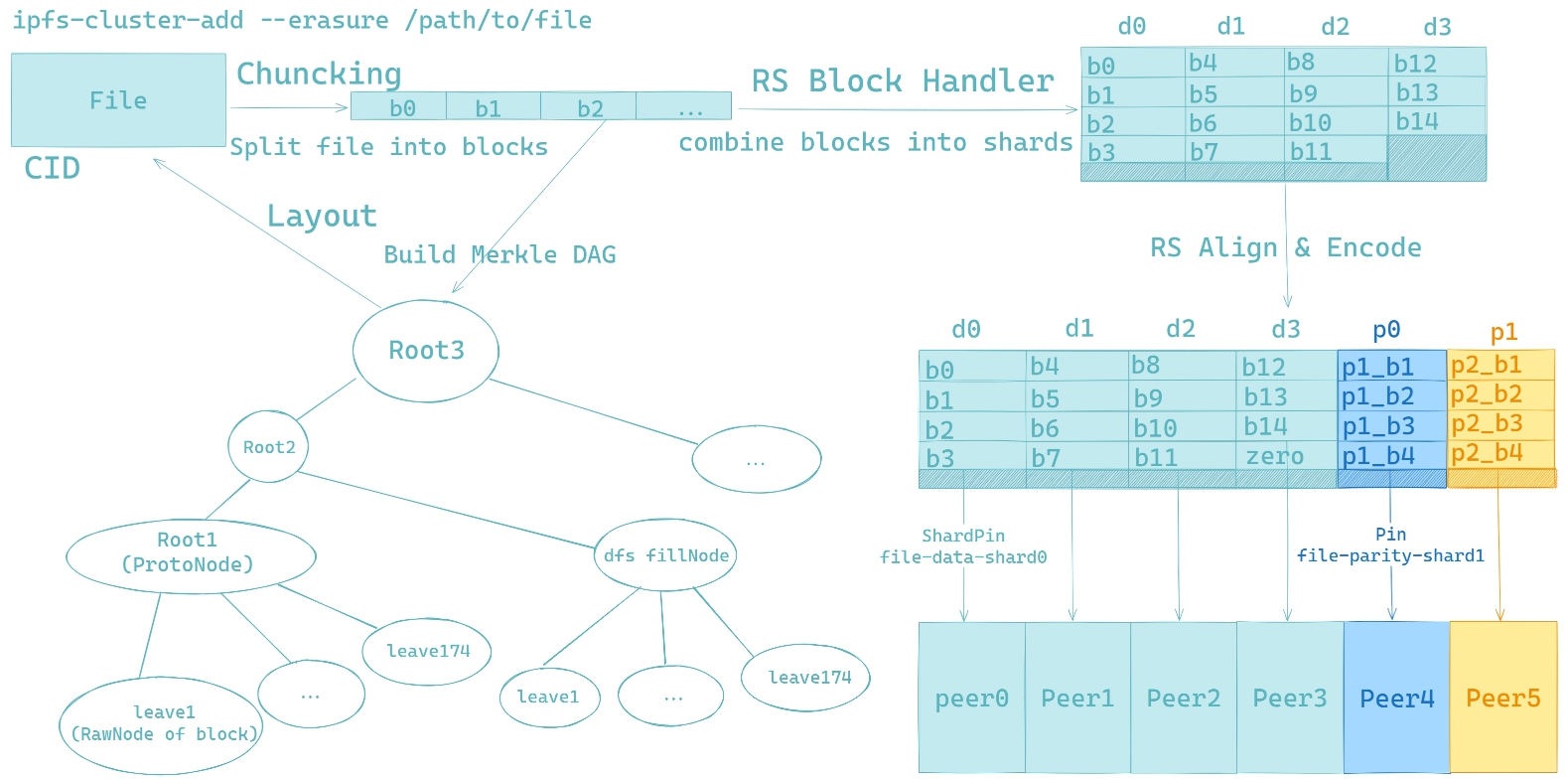
在 IPFS Cluster 而不在 IPFS 直接进行 EC 的原因
- IPFS 无法控制其他节点实际存储的块,因此无法起到纠删码分散容错的效果。
- IPFS Cluster 提供了很多节点之间同步和交互的功能,能维护一个集群一致的分片分配元数据。
- 生成的校验数据会破坏原文件的 Merkle DAG,需要改动很多接口和细节。
但是目前在 IPFS Cluster 上使用 EC 也有一个很令人难受的缺点:因为默认的添加文件方式通过一个 io.Reader 读入数据,切块,并构造 Merkle DAG,所以生成的校验块也是通过这样的方式添加到集群,这样会使得 pinset 比较大,可能在存储的文件过多的时候会对性能有影响。
考虑的优化是将这个 Merkle DAG 作为子节点拓展出一个新的 Merkle DAG,新的 Merkle DAG 需要包括校验数据,但 hack Merkle DAG 的方式以及 Merkle DAG 的实际结构还有待商榷。