GFS 是 Google 2003 年发表的论文,是分布式系统最早的大规模工业化实践。当时的背景是 Google 需要一个适用于各种 application 的 Global 存储系统。
GFS 的目标
- 部署在廉价机器,需要自动监控、容错和恢复。
- 能够处理海量大文件,数十亿 GB 级别的文件组成的 TB 级快速增长的数据。
- 总是批量读取数据,侧重于顺序读取和 Append 数据,因此没有太大的内存加速需求。
- 能够自动让数据在机器之间同步。
Design Overview
iterface
create, delete, open, close, read, write, snapshot, record append.
特别是 multiple clients 各自持锁的并发 append 操作,引入了多路归并和生产者-消费者实现。
Architecture
一个 master 和多个 chunkserver,master 包含 file namespace,file 进来的时候会被切分成若干个 chunks,每个 chunk 被分配一个不可变的 64bit 的 chunk handler。
client 可以和 master 交互找到对应的 chunk,然后再与 chunkserver 交互,获取保存在 linux file system 的 chunk data。
chunk size
64MB,比较大,因为面向的是大文件存储,对于热点文件不太友好,因为热点 chunk 需要处理很多节点的请求。
metadata
Master 存储的元数据主要为文件和 chunk namespace,文件到 chunk 的映射,每个 chunk 的 Replica 的位置。前两者可以通过日志备份进行持久化,日志过大后,可以压缩成类似于 B-Tree 的结构,并建立 checkpoint,从硬盘中读取压缩的数据直接到内存后,再通过 checkpoint 执行日志;而 chunk 的 Replica 的位置信息是不确定的,需要每个 chunkserver 告诉 Master。
Consistency Model
GFS 的一致性是比较宽松的,不保证所有副本在字节上完全一致。如果一个写入操作成功执行,并且没有并发写操作的干扰,所影响的区域是 “defined”;如果是并发写,那么所影响的区域会被标记 “consistent but undefined”,因为并发操作时会被新的操作覆盖,比如并发的 append-at-least-once 可能需要 处理偶然的 padding 和重复数据,这部分的数据就会被标记;而失败的变更,会让区域进入到不一致的状态:clients 在访问同一个内容的时候可能会看到不同的数据。
System Interactions
Leases and Mutation Order
日志的顺序由 Master 指定的 Primary chunkserver 确定,一个写操作的流程如下,主要特点是 数据流和控制流分离。
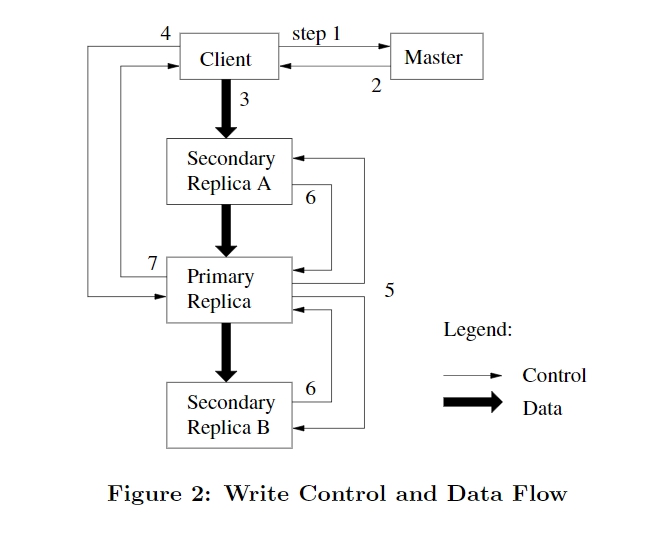
GFS 的 client 先与 Master 交互,获得 chunkserver 的位置,client 再将数据推送到某个 chunkserver,chunkserver 会继续将数据串行地推送到其他 chunkserver,所有副本接收了数据后,client 会发送写请求给 primary chunkserver,标识之前传输的数据, Primary 会根据这些数据的所有修改根据请求的序列进行串行化处理,按顺序应用到本地,再将这些请求发送到其他 chunkserver。
若过程出现错误,直接返回给 client 让其重试。
Atomic Record Appends
原子化的 append,从某个偏移量开始 append。如果数据会使得 chunk 超过 64MB,primary chunkserver 会让 client 在下一个 chunk 重试。GFS 会在某个 chunkserver 写入失败的时候抛出异常,让 client 重试,client 重试的时候会从某个偏移量开始覆盖数据,能够保证执行完这个请求后变动的数据是一致的。
Snapshot
快照能快速地保存某个文件或者目录,实现原理与 COW 类似。Master 收到快照请求的时候,先撤销之前发送给 primary chunkserver 的快照部分的租约,以便快速触发数据复制,然后将 chunk 的引用计数加一,在 chunk 写入的时候,发现 chunk 的引用计数大于一,就会在本地复制 chunk,并且 primary chunkserver 也会发送复制 chunk 的请求给其他 chunkserver,然后在新的 chunk 上继续写入。
Master Operation
Namespace management and locking
gfs 的锁是针对于命名空间的,并且 master 在操作某些数据前,需要得到对应命名空间的锁的集合。
首先 gfs 在逻辑上会通过前缀压缩路径查找表,master 在获取/a/b/c/d 的写锁时候,需要先获得/a 的读锁,再获得/a/b 的读锁…最后得到/a/b/c/d 的写锁。
这样的一个好处是可以执行某个目录下的并发操作。
gc
文件删除后,先标记,Master 定期扫描后再清除,但执行两次相同的删除后会直接物理删除,释放空间。